Chapter 30
Commands for Making Small Bases for Ideals: Remove Redundant
A Gröbner Basis can be infinite. Even when a Gröbner Basis is finite, it can be very large
and therefore difficult for a person to digest. One often finds that there are many relations
which are generated which do not enhance our understanding of the mathematics. In many
cases we want a basis for an ideal which is minimal (i.e., has smallest cardinality) or which
is minimal as a subset of a given basis. We, therefore, find it helpful to take a list of rules
which are generated by the GB algorithm and make them smaller. Consider the following
example.
Example 30.1 A GB generated by the set {PTP -TP,P2 -P} is the set {PTnP -TnP : n ≥
1}∪{P2 - P} regardless of the term order used. No smaller GB exists.
Here just two relations generate infinitely many. One way to view this example is that the computer
discovers that if a subspace (represented by ran(P) in the computation) is invariant for a linear
transformation T, then it is invariant for Tn for every n ≥ 1.
The GB algorithms tries to generate this infinite set of relations and at any time has generated a finite
subset of them. When we are trying to discover a theorem or elegant formulas, often these relations having
higher powers are irrelevant and clutter the spreadsheet which merely serves to confuse the
user.
This introduces the next topic which is shrinking a set of relations to eliminate redundancy.
Our desire is to take the generated basis and to remove mathematical redundancy from the
generating set without destroying the information which was gained while running the GB
algorithm.
We have two lines of attack on this problem. In this chapter we describe one which is embodied in the
command RemoveRedundant. In Chapter 21 we describe another approach.
30.1 Removing excess relations
30.1.1 Introduction
Our first line of attack works only when the set of relations under consideration has been generated by
NCMakeGB and then only either
-
- (1) The history was recorded right after using NCMakeGB via the WhatIsHistory command. OR
-
- (2) There have been no calls to NCMakeGB (either directly or indirectly) since the set of relations
was generated.
This approach is very fast.
If one has created a set of relations G by using NCMakeGB, then one can use history
(gotten by the WhatIsHistory command — see 29.2.1 recorded during the run of NCMakeGB
to find a smaller subset of G which generates the same basis. The essential idea is to take
the history from the previous run of NCMakeGB and use it to construct a directed acyclic
graph (DAG) representing the information. Then a fast combinatorial DAG search can be
done.
Note that the WhatIsHistory command only records one way in which a certain relation is generated.
For example, suppose that p5 is an S-polynomial of p1 and p2 and p5 is not reduced. It may also be the
case the p5 is an S-polynomial of p3 and p4 and p5 is not reduced. If the program computed p5 by taking
the S-ppolynomials of p1 and p2 first, then the fact that p5 is an S-polynomial of p3 and p4 will not be
recorded.
30.1.2 RemoveRedundant[]
-
- Aliases: None
-
- Description: RemoveRedundant[] calls RemoveRedundant[aListOfPolynomials,history] with the
default correct choices for aListOfPolynomials and history.
-
- Arguments: None
-
- Comments / Limitations: WARNING: The execution of this command depends upon the last
NCMakeGB run which was executed. Some commands call NCMakeGB as they run such as
SpreadSheet (subsection 15.2.1) and SmallBasis 21.1.1.
30.1.3 RemoveRedundant[aListOfPolynomials,history]
-
- Aliases: None
-
- Description: RemoveRedundant[aListOfPolynomials,history] generates a subset P of
aListOfPolynomials which generates the same ideal as aListOfPolynomials. We
conjecture that this is a smallest such set whose descendents in the history DAG contain
aListOfPolynomials. We conjecture that this property charachterizes P uniquely. This
command is faster while maybe not as powerful at reducing as ShrinkBasis since this
command relies on the history of how the GB was generated and it just extracts key ancestors.
That is why the list history is included to tell the routine how the various polynomials were
generated. History must have been recorded using the WhatIsHistory command from the run
of GB algorithm which produced aListOfPolynomials.
-
- Arguments: history is an output from the WhatIsHistory command. aListOfPolynomials is a list
of polynomials.
-
- Comments / Limitations: WARNING: The history one gets from the WhatIsHistory command
comes from the last run of the NCMakeGB command. The NCMakeGB command is called
by several other commands such as NCProcess (subsection 15.2.1 and SmallBasis and its
variants 21.1.1.
30.1.4 RemoveRedundentByCategory[]
-
- Aliases: None
-
- Description: RemoveRedundentByCategory[] calls
RemoveRedundentByCategory[aListOfPolynomials, history] with the default correct choices
for aListOfPolynomials and history.
-
- Arguments: None
-
- Comments / Limitations: It is wise to execute WhatIsHistory to set history right after you call
NCMakeGB. WARNING: This command executes on the last NCMakeGB run which was
executed. Some commands call NCMakeGB as they run, like SpreadSheet (subsection 15.2.1)
30.1.5 RemoveRedundentByCategory[ aListOfPolynomials, history]
-
- Aliases: None
-
- Description: RemoveRedundentByCategory[aListOfPolynomials,history] generates a subset P of
aListOfPolynomials which generates the same ideal as aListOfPolynomials. It is best thought
of in the context of RegularOutput or a spreadsheet. Recall?? the digested relations are the
polynomials involving no unknowns, single variable expressions, together with user selected
relations. Let the digested relations from the list aListOfPolynomials be called D. Suppose
we denote each category of undigested polynomials by Xj where j runs from 1 to the number
of these categories. Then RemoveRedundentByCategory[aListOfPolynomials, history] is the
union over j of RemoveRedundent[Union[D, Xj], history].
-
- Arguments: aListOfPolynomials is a list of polynomials. history is a list from the command
WhatIsHistory.
-
- Comments / Limitations: It is wise to execute WhatIsHistory to set history right after you call
NCMakeGB. WARNING: The history one gets from the WhatIsHistory command comes from
the last run of the NCMakeGB command. The NCMakeGB command is called by several
other commands such as NCProcess (subsection 15.2.1).
30.2 Discussion of RemoveRedundent command
RemoveRedundent requires a history and a list of polynomials. NCMakeGB records part of
what it is doing during its computation and that can be used to determine some facts about
ideal membership. This history can be though of as a directed acyclic graph (abbreviated as
dag).
The the list of polynomials is a subset V of all of the nodes and the output of RemoveRedundent is
another set R of nodes v in V . Let √ denote a connected path which runs from v backward in time
until it reaches a leaf. Now 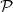 ends at v in the set V and may as we go backwards along it in
time leave V then come back etc. Let v() denote the earliest node of in V . It belongs to
R. Indeed, R = {v() for all maximal connected forward flowing paths ending in V }. For
example, if some path ends in v and the node immediately before v is not in V , then v is in
R. Now we give more formal statements and about how the RemoveRedundent algorithm
works.
ends at v in the set V and may as we go backwards along it in
time leave V then come back etc. Let v() denote the earliest node of in V . It belongs to
R. Indeed, R = {v() for all maximal connected forward flowing paths ending in V }. For
example, if some path ends in v and the node immediately before v is not in V , then v is in
R. Now we give more formal statements and about how the RemoveRedundent algorithm
works.
Let p1,…,pn 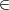 K[x1,…,xn]. Let T be a tree on the nodes {1,…,n}. We say that the tree represents the
development of p1,…,pn if it is the case that for every j = 1,…,n either
K[x1,…,xn]. Let T be a tree on the nodes {1,…,n}. We say that the tree represents the
development of p1,…,pn if it is the case that for every j = 1,…,n either
-
- (1) j is a leaf of the tree OR
-
- (2) there exists a S-polynomial s coming from pa and pb and k1,…,kr {1,…,n} such that
-
- (a) {a,b,k1,k2,…,kr} is the set of children of j in the tree T, and
-
- (b) there exist polynomials q1,…,qr such that s →pk1q
1 →pk2
 →pkrq
kr = pj.
→pkrq
kr = pj.
OR
-
- (3) there exist a and {k1,…,kr} such that {a,k1,…,kr} are the children of j and there exist
polynomials q1,…,qr such that pa reduces to q1 by applying the rule associated to the
polynomial pk1, q1 reduces to q2 by applying the rule associated to the polynomial pk2,
…, qr-1 reduces to qr by applying the rule associated to the polynomial pkr such that
pa →pk
1q1 →pk2
 →
pkrqr = pj.
→
pkrqr = pj.
Now suppose that T is a tree on {1,…,n} and it represents the development of p1,…,pn. If
j is the root of the tree and k1,…,kr are the leafs of T, then pj lies in the ideal generated
by pk1,…,pkr. In fact, pa lies in the ideal generated by pk1,…,pkr for every a such that both
1 ≤ a ≤ n.
Now, if a tree T represents the development of p1,…,pn and one chooses a subset {k1,…,kr}{1,…,n},
then one can consider the largest subgraph of T for which each node kℓ has no edge leading from it. Each
connected component of this subgraph will be a tree. Let To be such a connected component of T
and {ℓ1,…,ℓw} be the nodes of To. It is clear that the tree To represents the development of
pℓ1,…,pℓw.
This is the key to the function RemoveRedundent. This function takes a tree T which
represents the development of p1,…,pn and a list of nodes {ℓ1,…,ℓw}. The algorithm proceeds as
follows.
Let result = {ℓ1,…,ℓw};
Let unchanged = False;
while(unchanged)
unchanged = False;
temp = result;
while(unchanged is False and temp is not the empty set)
Pick ℓ temp;
Let temp = temp\{ℓ};
More here ? MARK whats this mean
end while
end while
30.3 Examples
This shrinking is done using the commands RemoveRedundent and SmallBasis.
30.4 First Example
For example, after loading the files NCGB.m, SmallBasis3.m (§21.1.1) and RemoveRedundent.m
(§30.1.2), we can execute the commands to compute a subset of a Gröbner Basis for the set of relations
{p **p - p,p **a **p - a **p}:
In[2]:= SetKnowns[a,p]
In[3]:= {p**p-p,p**a**p - a**p}
Out[3]= {-p + p ** p, -a ** p + p ** a ** p}
In[4]:= NCMakeGB[%,4]
|
Out[4]= {-p + p ** p, -a ** p + p ** a ** p, -a ** a ** p + p ** a ** a ** p,
> -a ** a ** a ** p + p ** a ** a ** a ** p,
> -a ** a ** a ** a ** p + p ** a ** a ** a ** a ** p,
> -a ** a ** a ** a ** a ** p + p ** a ** a ** a ** a ** a ** p,
> -a ** a ** a ** a ** a ** a ** p + p ** a ** a ** a ** a ** a ** a ** p,
> -a ** a ** a ** a ** a ** a ** a ** p +
> p ** a ** a ** a ** a ** a ** a ** a ** p,
> -a ** a ** a ** a ** a ** a ** a ** a ** p +
> p ** a ** a ** a ** a ** a ** a ** a ** a ** p,
> -a ** a ** a ** a ** a ** a ** a ** a ** a ** p +
> p ** a ** a ** a ** a ** a ** a ** a ** a ** a ** p,
> -a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** p +
> p ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** p,
> -a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** p +
> p ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** p,
> -a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** p +
> p ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** p,
> -a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** p +
> p ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** p\
> , -a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a **
> a ** p + p ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a **
> a ** a ** a ** p, -a ** a ** a ** a ** a ** a ** a ** a ** a ** a **
> a ** a ** a ** a ** a ** p +
> p ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a **
> a ** a ** p, -a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a **
> a ** a ** a ** a ** a ** p +
> p ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a **
> a ** a ** a ** p}
|
The command SmallBasis takes this (or any) set of relations and shrinks it down to a
smaller set of relations which generate the same ideal. One must have a monomial order set
because SmallBasis (§21.1.1) calls NCMakeGB. SmallBasis returns a subset of the original
set of relations. In the example below the SmallBasis command shows that the ideal
generated by the set Out[4] equals the ideal generated by {-p + p **p,-a **p + p **a **p}.
In[5]:= SmallBasis[%4,{},4];
Out[5]= {-p + p ** p, -a ** p + p ** a ** p}
|
Unfortunately in larger examples, SmallBasis is very slow which prompts the development of a more
specialized command RemoveRedundant. This can be run only after NCMakeGB has been run because it
uses the history of how the GB was produced. This history is equivalent to a tree which tells what relation
came from what other relations RemoveRedundant uses only tree search methods so it is faster than
SmallBasis.
As one sees below the information required for RemoveRedundant is a subset of the last GB produced
in your session.
Before calling RemoveRedundent, one must acquire the history of the last GB produced in your
section. This takes 2 commands which we now illustrate and which we explain afterward.
In[5]:= WhatAreNumbers[]
Out[5]= {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17}
In[6]:= WhatIsHistory[%]
|
Out[6]= {{1, p ** p -> p, {0, 0}, {}},
> {2, p ** a ** p -> a ** p, {0, 0}, {}},
> {3, p ** a ** a ** p -> a ** a ** p, {2, 2}, {2}},
> {4, p ** a ** a ** a ** p -> a ** a ** a ** p, {3, 2}, {2}},
> {5, p ** a ** a ** a ** a ** p -> a ** a ** a ** a ** p, {3, 3}, {3}},
> {6, p ** a ** a ** a ** a ** a ** p -> a ** a ** a ** a ** a ** p,
> {5, 2}, {2}}, {7, p ** a ** a ** a ** a ** a ** a ** p ->
> a ** a ** a ** a ** a ** a ** p, {5, 3}, {3}},
> {8, p ** a ** a ** a ** a ** a ** a ** a ** p ->
> a ** a ** a ** a ** a ** a ** a ** p, {5, 4}, {4}},
> {9, p ** a ** a ** a ** a ** a ** a ** a ** a ** p ->
> a ** a ** a ** a ** a ** a ** a ** a ** p, {5, 5}, {5}},
> {10, p ** a ** a ** a ** a ** a ** a ** a ** a ** a ** p ->
> a ** a ** a ** a ** a ** a ** a ** a ** a ** p, {9, 2}, {2}},
> {11, p ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** p ->
> a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** p, {9, 3}, {3}},
> {12, p ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** p ->
> a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** p, {9, 4}, {4}}\
> , {13, p ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a **
> p -> a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** p,
> {9, 5}, {5}}, {14, p ** a ** a ** a ** a ** a ** a ** a ** a ** a **
> a ** a ** a ** a ** p ->
> a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** p,
> {9, 6}, {6}}, {15, p ** a ** a ** a ** a ** a ** a ** a ** a ** a **
> a ** a ** a ** a ** a ** p ->
> a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** p
> , {9, 7}, {7}}, {16, p ** a ** a ** a ** a ** a ** a ** a ** a ** a **
> a ** a ** a ** a ** a ** a ** p ->
> a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a **
> a ** p, {9, 8}, {8}}, {17,
> p ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a **
> a ** a ** a ** p ->
> a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a ** a **
> a ** a ** p, {9, 9}, {9}}}
|
The call to RemoveRedundent is:
In[7]:= RemoveRedundent[Out[4],Out[6]];
Out[7]= {-p + p ** p, -a ** p + p ** a ** p}
|
The first command recalls the number associated to all of the relations which occurred during
the previous run of Mora’s algorithm. The second command gives the ancestory and other
information related to relations 1, 2, …. One could have used any list of numbers (between 1 and 17)
as the argument to the WhatIsHistory command and obtained only the history of those
relations.
30.5 Second Example
As a second example, after loading the files NCGB.m, SmallBasis3.m and RemoveRedundent.m,
we can execute the following commands to compute a Gröbner Basis for the set of relations
{x2 - a,x3 - b}:
In[3]:= SetKnowns[a,b,x]
In[4]:= NCMakeGB[{x**x-a,x**x**x-b},10]
Out[4]= {-a + x ** x, -b + a ** x, -b + x ** a, -a ** a + b ** x,
> -a ** b + b ** a, -a ** a + x ** b, -b ** b + a ** a ** a}
|
Now, one might want to find a smaller generating set for the ideal specified above. The following
command does that and took 9 seconds using the C++ version of the code.
In[5]:= SmallBasis[%4,{},3]
Out[5]= {a ** x -> b, x ** x -> a}
|
Alternatively, one can use the command RemoveRedundent to generate the same result in 2 seconds. There
are two steps which need to be performed before calling RemoveRedundent.
In[6]:= WhatAreNumbers[]
Out[6]= {1, 2, 3, 4, 5, 6, 7}
In[7]:= WhatIsHistory[%]
|
Out[7]= {{1, a ** x -> b, {0, 0}, {}}, {2, x ** x -> a, {0, 0}, {}},
> {3, b ** x -> a ** a, {1, 2}, {}}, {4, x ** a -> b, {2, 2}, {1}},
> {5, x ** b -> a ** a, {4, 1}, {3}}, {6, b ** a -> a ** b, {3, 2}, {1}},
> {7, a ** a ** a -> b ** b, {3, 4}, {}}}
|
The call to RemoveRedundent is:
In[8]:= RemoveRedundent[%4,Out[12]]
Out[8]= {a ** x -> b, x ** x -> a}
|
30.6 Smaller Bases and the Spreadsheet command
Here is a session which does roughly what the spreadsheet command does. For more detail see Chapter
15
In[11]:=NCMakeGB[FAC,2];
In[11]:=SmallBasisByCategory[RemoveRedundant[%] ];
|
The next command tries to see if any of the undigested relations can be made simpler using the digested
relations
In[12]:=NCSimplifyAll[%11, DigestedRelations[%11] ];
|
Finally we output the result to the file “SecondOutputForDemo”??.
In[13]:=RegularOutput[%12, "SecondOutputForDemo"];
|
Now we return to the strategy demos of Chapter 15.
Inserting the command RemoveRedundant inside of small basis may change the answer, but it yields
the same answer as SmallBasis would have given with one particular order on the set of relations given as
input. All this assumes that the number of iterations is large. Inserting RemoveRedundant saves much
computer time.